Perplexity AI 会成为下一代搜索引擎范式么
Perplexity 体验
Perplexity据说是 Nvidia 掌门人黄仁勋每天都在用的AI工具。年初与贾扬清关于500行Lepton ai代码实现其核心功能之间的风波,又为Perplexity赚足了眼球。之前一直是在网上看到关于这个工具的消息,甚至有讨论提出了google killer这么高的评价,这让人不得不腾出时间来了解一下这个工具。
打开 Perplexity网站, 界面非常简洁,页面中心映入眼帘的“Where knowledge begins”的slogan,确实充满了颠覆传统搜索的气质。slogan下方就是常见的搜索框。
首先试用一下:
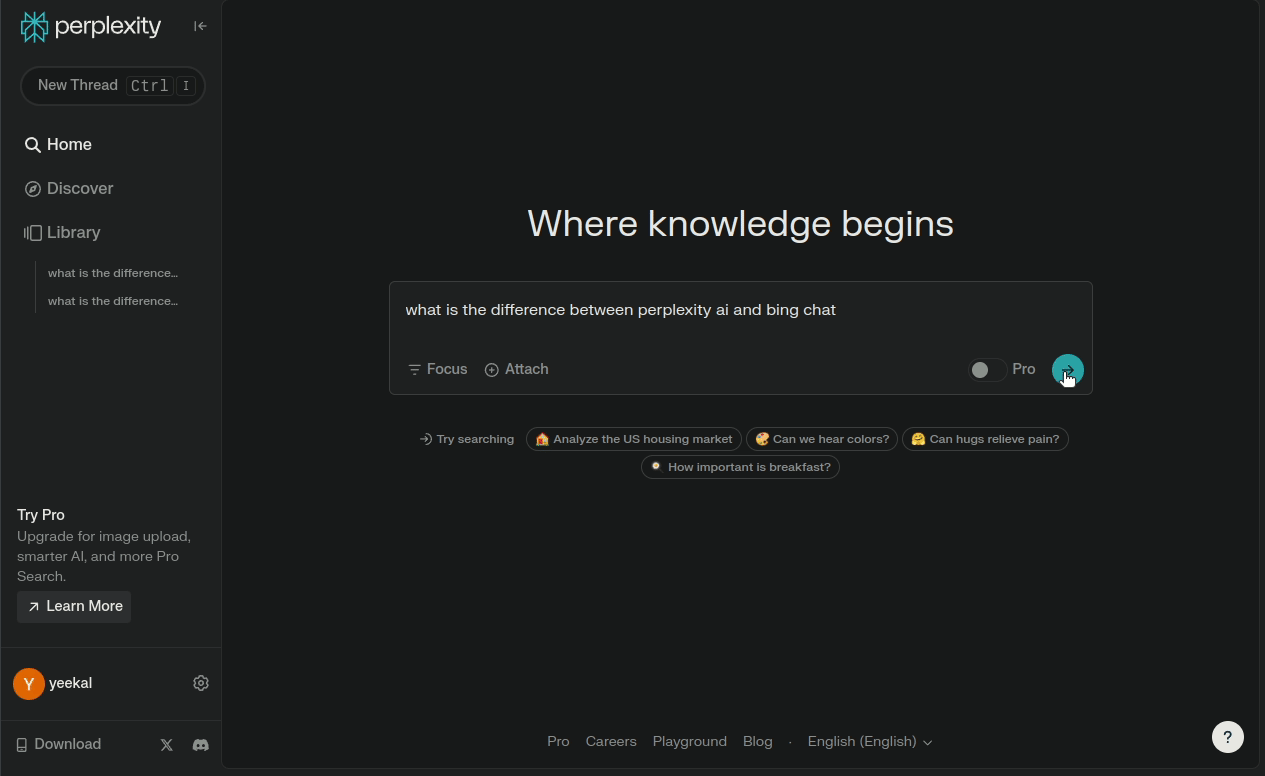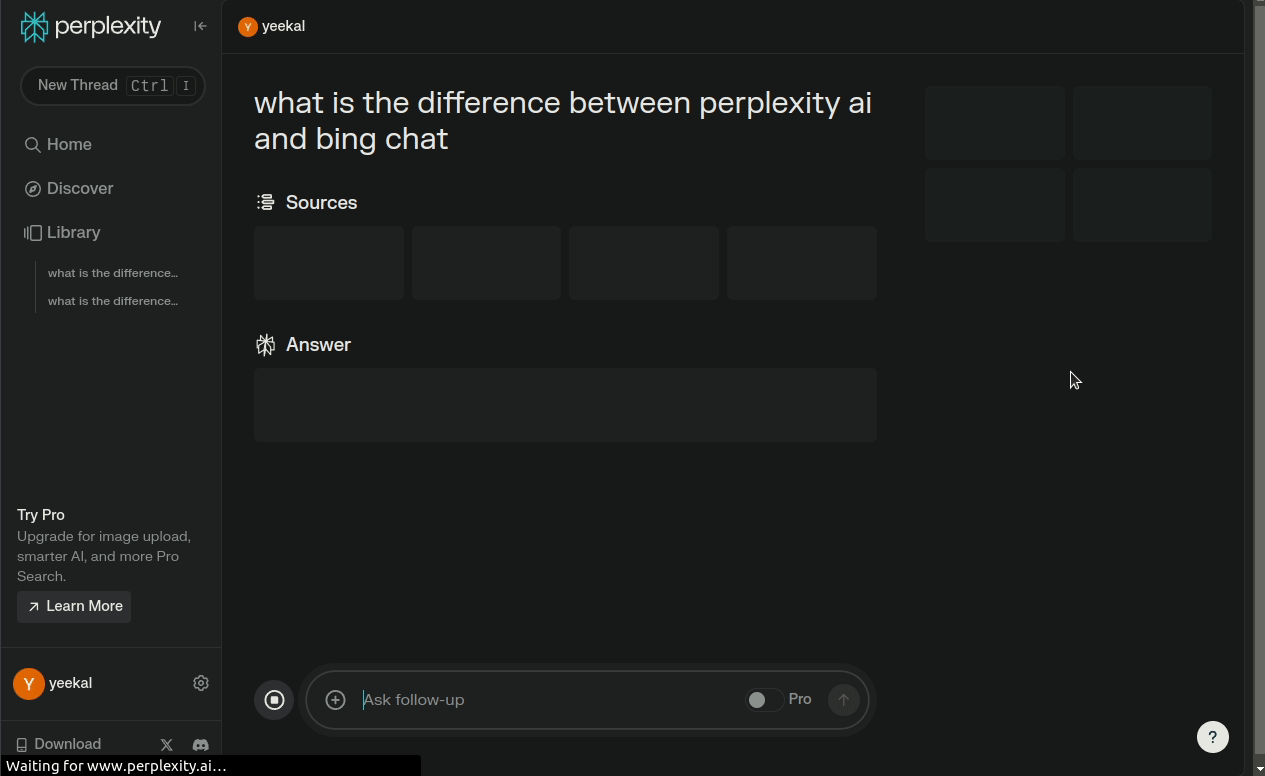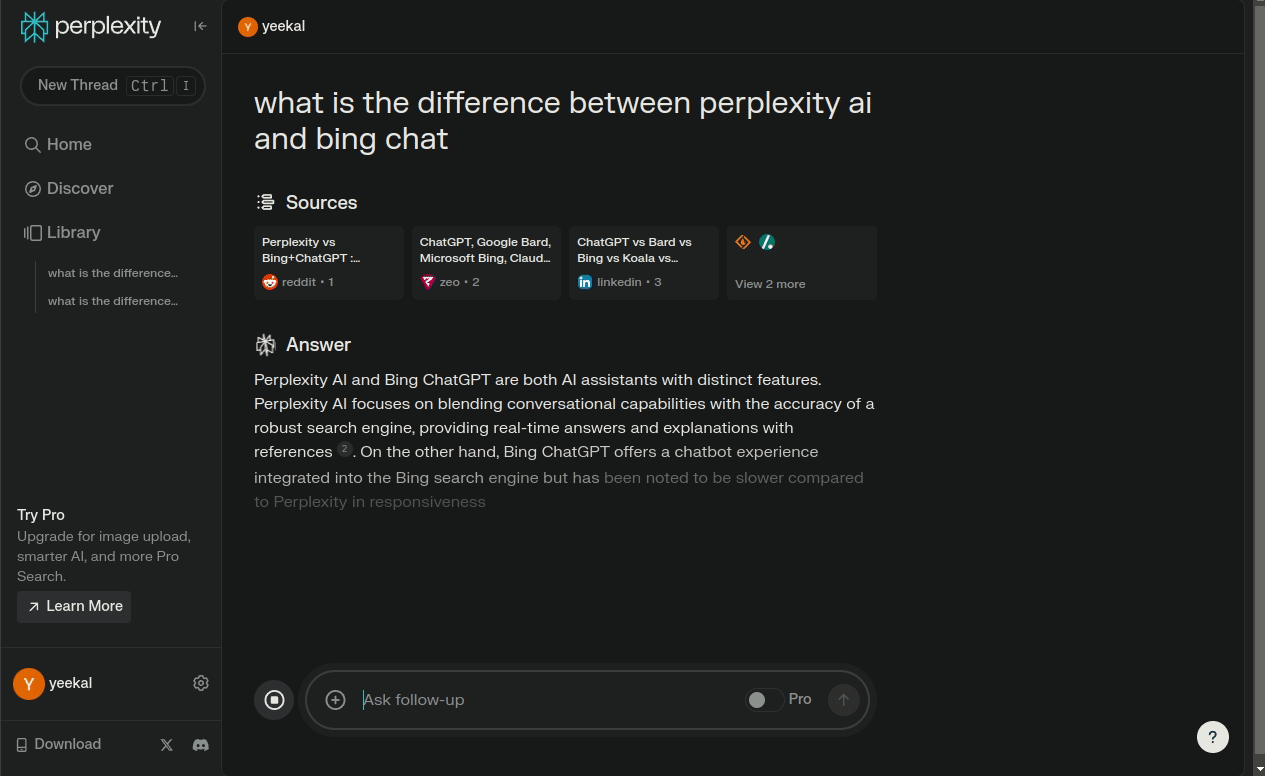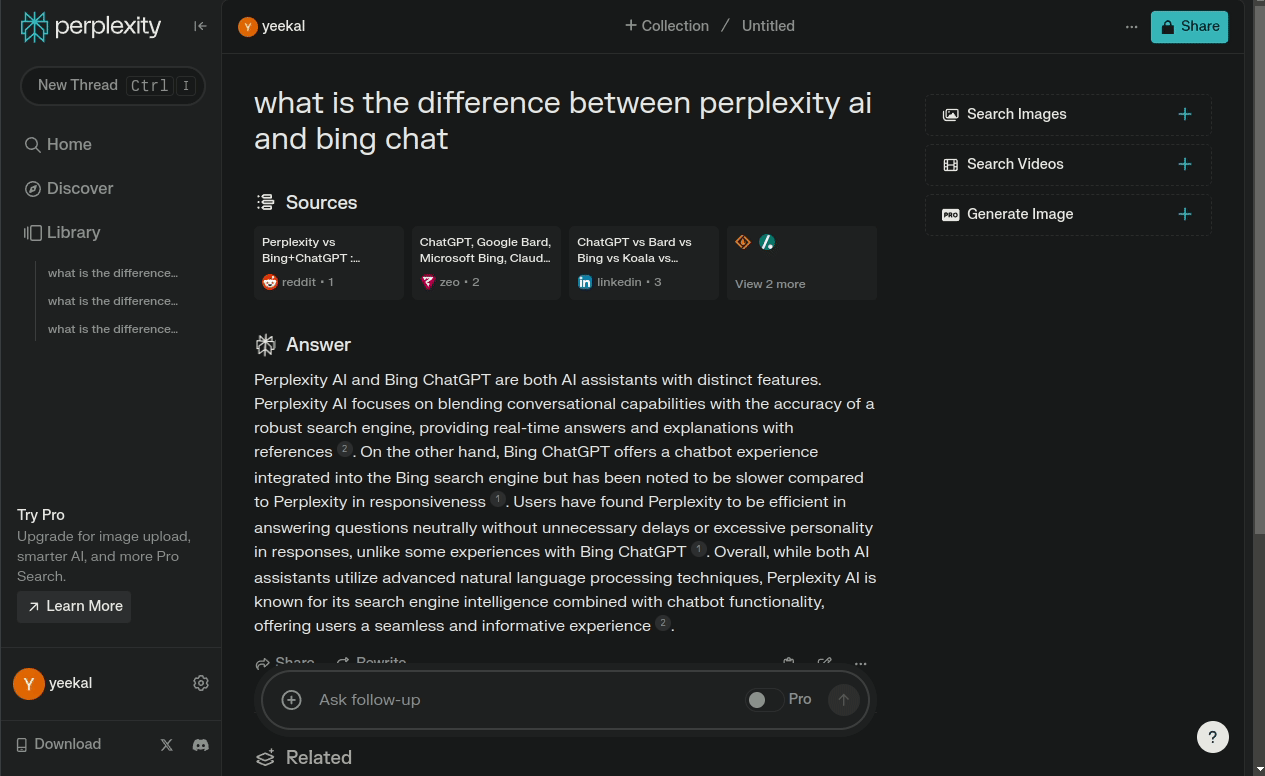
流式对话输出跟ChatGPT的体验很类似,但是不一样的是Perplexity会给出引用源,并且在回答中标注引用源的位置。这样的设计让人感觉回答的结果更加的可信。事实上,Perplexity的设计理念就是把大模型能力和实时互联网信息相结合,让用户在实时网络信息里体验大模型的能力。
在搜索框下方的Focus按钮里可以选择限定搜索域,比如 学术领域,写作领域,wolfram alpha,YouTube,Reddit等。在Attach里可以关联本地的图片文本或者PDF文件作为输入。
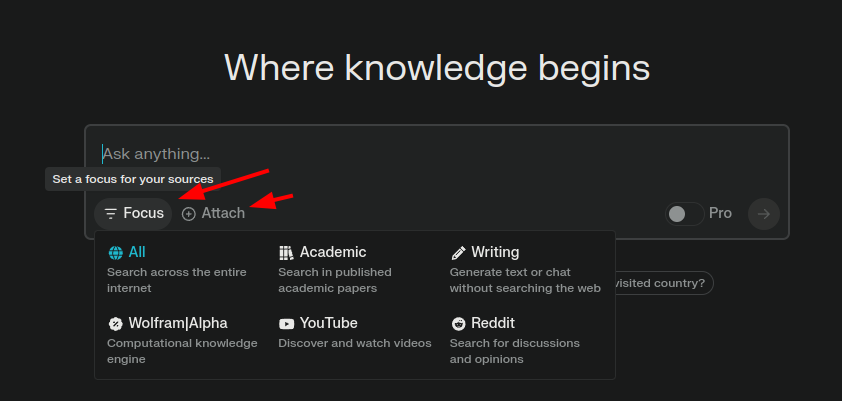
Perplexity的底层能力结合了GPT, Claude以及Mistral模型。其中免费基础版使用的是GPT-3.5, 而氪金PRO版则可以使用GPT-4, Claude 3, Mistral Large等更加强大的模型。
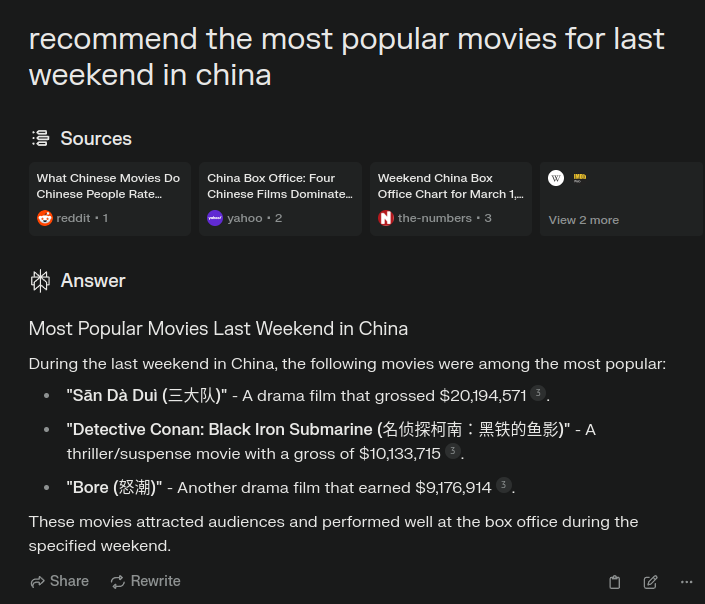
相比与单纯的GPT-4模型对于实时信息的滞后,Perplexity在关于实时信息的问答上比GPT-4更加的优秀,比如电影上映时间,股票价格,天气查询等等。下述表格是同一问题recommend the most popular movies for last weekend in china在chatgpt,google,Perplexity三个平台的回答对比。可以看出chatgpt完全放弃挣扎,但是提供了一系列可以进一步查询的网站;google搜索里几乎都是跟据关键词索引的文章列表;而Perplexity则直接给出了上映的电影列表。不过Perplexity的回答的都是2023年的电影,并且信息源里面也都是海外网站的信息,可以看出Perplexity在地域性的信息整合上还不够友好。
| chatgpt | Perplexity | |
|---|---|---|
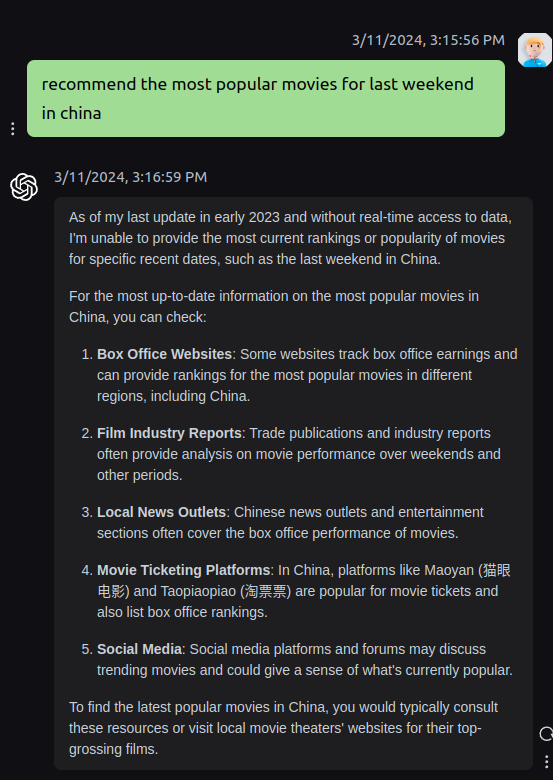 |
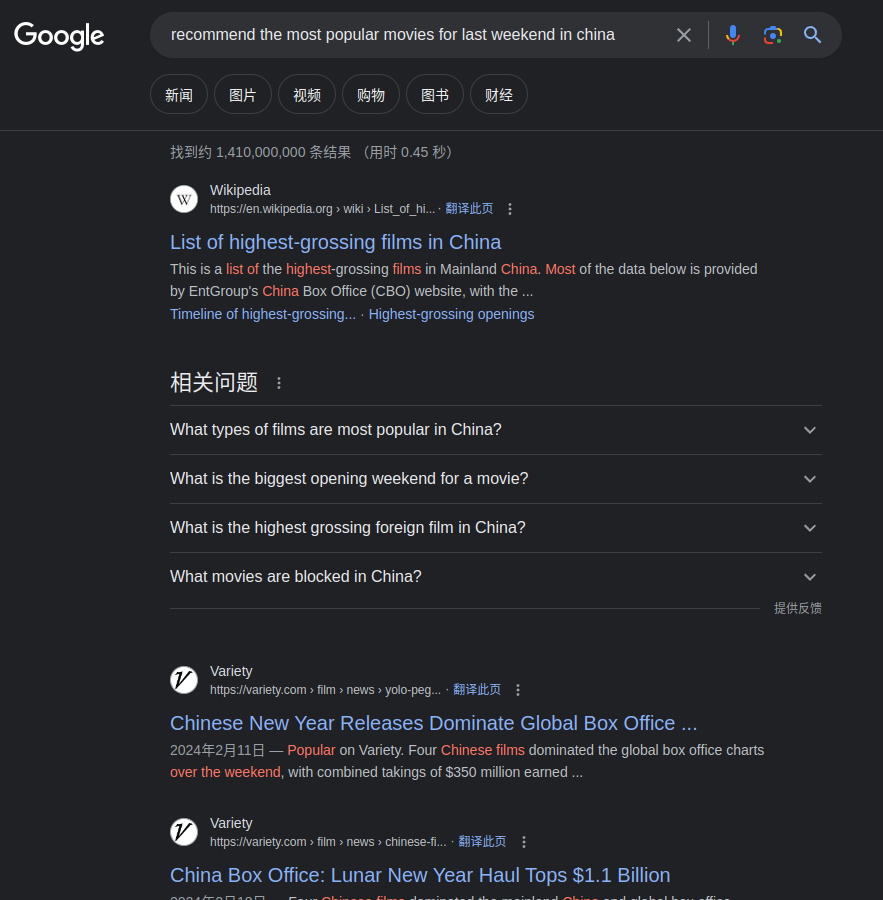 |
 |
那么,Perplexity AI 会成为下一代搜索引擎范式么?
传统的搜索引擎主要解决如何从海量的信息库里面检索出目标信息,技术手段主要是通过字符串匹配。无论是全网搜索还是垂域搜索,这一技术的应用都渗透其中。当前应用最广的搜索引擎库ElasticSearch其底层就是通过分词,构建倒排索引,达到快速匹配搜索词的目的。
比如数据库里有三个文本:
- 小明是个好学生
- 小红不会打篮球
- 小刚是体育能手
在传统的搜索引擎里,如果搜索小明,那么会返回第一个文本;如果搜索小,那么会返回所有文本;如果搜索好学生,那么会返回第一个文本。这种搜索方式深入到我们生活的方方面面。比如淘宝购物,AppStore搜索应用,美团查找蛋炒饭商家等等。其中这些搜索词就是关键词,当前催生的SEO技术也是根据怎么更改商品或者页面的文本描述以达到提高目标关键词的匹配度的目的,从而提高曝光量。但是它的局限性在于,无法识别关键词之间的语义关联。比如如果你印象中有个学生经常考高分,你想搜索出来他是谁,如果输入考高分,可能不会有任何结果出来,虽然你的预期应该是返回第一个文本。这种方式无法发现考高分和好学生之间的语义关联。
在ChatGPT横空出世之前,人工智能在图片以及自然语言领域已经探索了很长一段时间。虽然这些探索没有达到当前大模型这么强大的能力,但是也小有成就。搜索引擎也在积极利用这些探索的成果。其中应用最广的就是词嵌入(word embedding)。词嵌入是把自然语言通过模型映射到一个高维空间,每个词由一个向量来表示,因此这也被称为词向量。这样就把文本的问题转移到了一个数学空间里,在这个空间里可以计算向量的距离,以远近表示两个词的关联度。这样语义关联的问题就被词嵌入解决了。在向量空间里,好学生和考高分的距离应该是较近的,但是考高分和体育能手的距离应该是较远的。这样通过词嵌入,搜索引擎就可以根据考高分的语义召回好学生的文本。
后来词嵌入逐渐去掉前缀词,变成了嵌入(embedding). Embedding 技术不仅仅局限于词,文本,段落,而是所有被模型作为输入的东西,比如图像。在图像领域,embedding技术可以把图像映射到一个高维空间,这样就可以计算图像之间的相似度。以此来实现图像搜索。比如你有一张机器人的图片,你可以通过图像搜索引擎找到相似的机器人的图片。
语义上的联系让搜索引擎的结果更加接近用户预期。但是大模型的出现确实让我们看到了另一种模式——直接回答用户的问题,而不再是给用户列出参考文档。搜索引擎在提取网络信息上是直接的,无损的,但是不会给用户建议,需要用户自己去查阅。而大模型通过训练过程具有强大的总结,学习和逻辑能力,但是不能保证旧有信息的准确性。Perplexity 再做的就是把两者结合在一起,一方面搜索引擎的结果页面在参考关联性上比全网无关联的数据更加有价值,而大模型利用自己博学的基础知识和搜索结果页面的专业知识通过逻辑分析再总结的方式直接呈现给用户结果。这就是Perplexity所要打造的局面。
在大模型时代,Perplexity 确实竖立了新一代的的搜索范式。但在当前,它的局限性还是非常受制于大模型的能力以及用户意图的理解。搜索结果给了模型一次更新知识的机会,但是模型底层的逻辑机制难以避免幻觉的产生。另一方面,大多数时候用户搜索都是很短的词,而不是完整的一句话,在这种情况下是否能理解用户的真实意图也是极具挑战性的。