Figure 01: 这不是特效,这是ChatGPT版的机器人

昨天夜里, Figure AI 发布了Figure 01机器人与人类交互的视频,立刻在网上引起大家的广泛关注。在ChatGPT加持下,Figure 01展现了无与伦比的对话和操作能力。
首先机器人能准确得识别出摆放在面前得物品并描绘出其所在的周围环境。能鉴别出来桌面上唯一可以吃得苹果。并灵活的交到人类手上。

捡垃圾的动作,利落,干脆,直接。它就像一个真实的人类那一哪个一只手扶着框,一手捡起垃圾团丢到框里。这不禁让市面上笨拙的机械手们汗颜到上个世纪。

让它收拾一下桌面,它直接旧识别出杯子和盘子应该各自在不同的位置,并分类放好。它甚至知道杯子倒着放,盘子需要卡在盘架上。在放杯子和盘子的时候观测到它其实并没有把物品“完美”地放到那个位置,而是放一个大概的位置,然后杯子和盘子在重力以及周围物品的撞击下逐渐晃动到一个稳定的位置,这很像人类的这种负反馈动作——人类其实无法准确得把手按照一个精准的路线移动,但是会在慢慢接近目标得时候逐渐纠正自己的动作,并利用自己对物理世界的理解让物品稳定下来。

以上都不是特效,也没有做降速剪辑,更不是远程遥控的结果,完全是机器人真实计算的动作。在Figure 01里,OpenAI提供了视觉和语言理解能力,而Figure AI则提供了机器人的动作规划和控制能力。两大技术的结合造就了Figure 01独一无二的物理世界交互能力,甚至有种科幻电影里的效果。
甚至有人预言AGI(Artificial General Intelligence,人工通用智能)将在半年内可能出现。
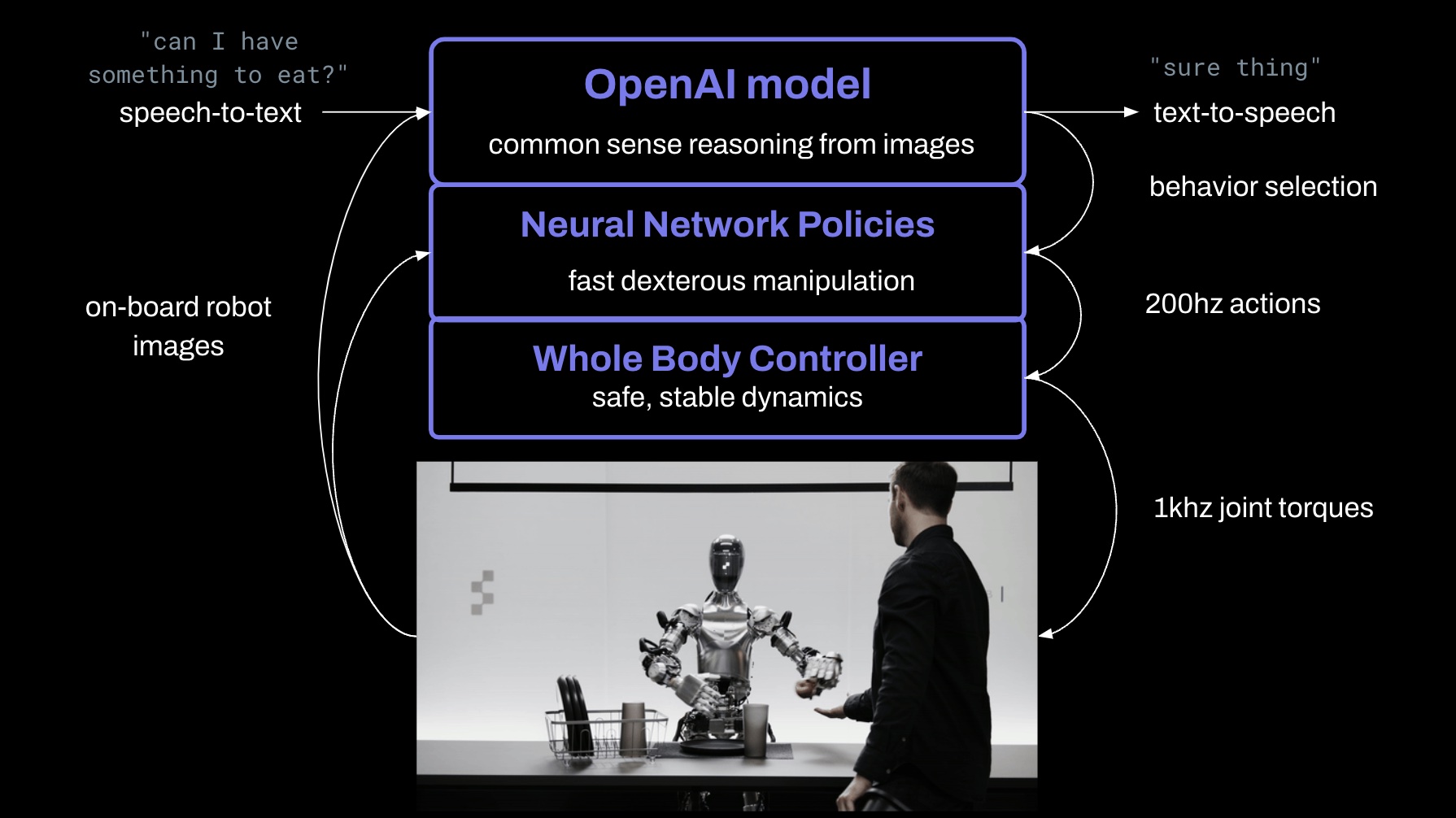
Figure AI 技术人员在twitter上透漏:所有行为都是通过学习获得的(非遥控操作),并且以正常速度(1.0倍速)运行。他们把机器人摄像头捕获的图像和内置麦克风捕捉到的语音转录文本输入到一个由OpenAI训练的大型多模态模型中,该模型能够理解图像和文本。模型处理整个对话的历史,包括之前的图像,以生成语言回应,这些回应通过文本转语音的方式回应给人类。另一个模型负责决定在机器人上运行哪种已学习的行为来规划动作已完成给定的命令。底层有一个全身控制器根据规划路径对机器人进行安全稳定的控制。整个过程如下图所示:
早在年初,Figure AI就表示他们的机器人已经能够以200HZ的速度运行端到端的网络,能够实现通过视觉图像到底层控制指令的映射。神经网络在图像和自然语言上已经实现了巨大的突破,而在机器人的运动规划上一直处于学术界狂欢但是实际工业上派不上用场的状态。Figure AI的这一突破意味着机器人有望在人工智能技术的支撑下在运动规划领域迎来新的变革。要实现AGI,机器人领域的技术革新是必不可少的一步。而Figure 01让我们又一次有机会接近这一目标。